
 English
English
Trong bài trước, phần phân tích dữ liệu đã được giới thiệu, 1 phần quan trọng tiếp theo trong mô hình là làm thế nào để ứng dụng học máy vào sản xuất và làm cho nó mang lại lợi ích cho doanh nghiệp. Có nhiều cách tiếp cận khác nhau để đưa công nghệ máy học vào nhà máy, dẫn đến tác động tích cực khác nhau. Bài viết này sẽ được chia thành ba phần chính. Phần đầu tiên giới thiệu một số định nghĩa về mô hình học máy và các loại mô hình học máy. Phần thứ hai đưa ra định nghĩa về từng loại mô hình đào tạo. Phần cuối cùng là về cách triển khai và cải thiện một mô hình học máy.
1. Định nghĩa “mô hình”
Đây là một thuật ngữ chính cần được hiểu rõ ràng. Thuật ngữ “mô hình” được sử dụng rộng rãi trong kinh doanh. Theo mục đích của bài viết này, “mô hình” được định nghĩa là sự kết hợp của thuật toán và cấu hình được sử dụng để đưa ra dự đoán mới dựa trên tập dữ liệu đầu vào. Nó được xem như là một hộp đen có thể nhận dữ liệu thô và đưa ra kết quả dự đoán. Một mô hình sẽ được đào tạo dựa trên một tập hợp dữ liệu. Nó sẽ được cung cấp một thuật toán có thể được sử dụng để suy luận và học từ nguồn dữ liệu được cung cấp.
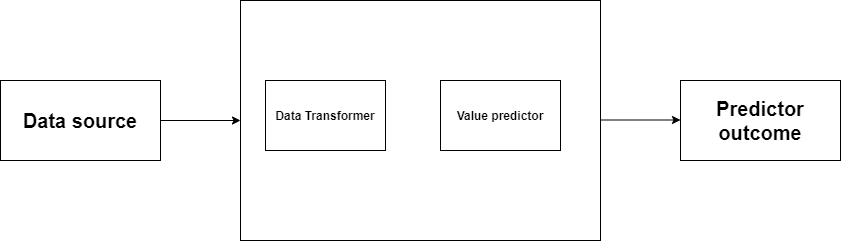
(Figure 1: Định nghia về mô hình)
Có rất nhiều công cụ, thư viện và chương trình phần mềm có thể tạo mô hình dễ dàng. Đối với ví dụ bài viết này, thư viện sklearn sẽ tập trung vào việc xây dựng các mô hình.
2. Các loại mô hình máy học
Học máy có thể được chia thành hai loại chính (tùy thuộc vào các vấn đề), đó là học có giám sát và học không có giám sát.
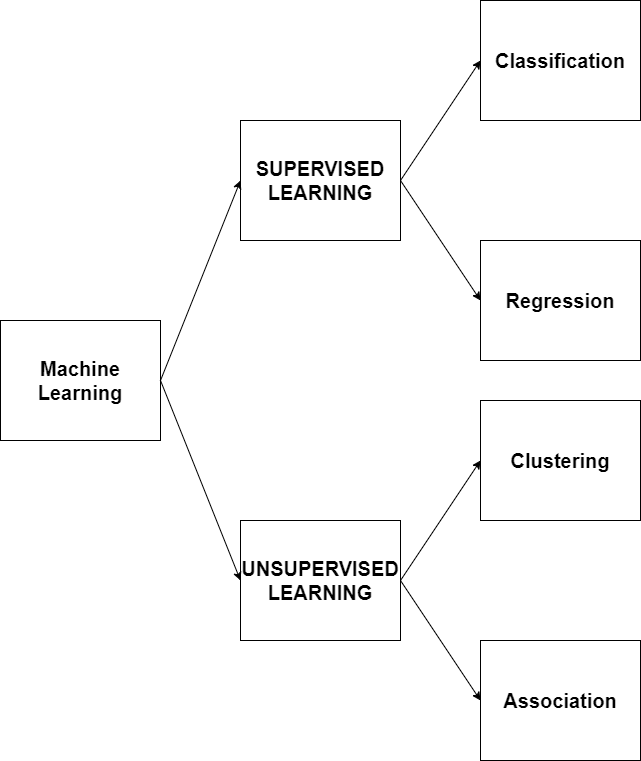
(Figure 2: Các loại bài toán học máy)
2.1 Học có giám sát.
Phần lớn các mô hình học máy thực tế sử dụng học có giám sát. Học có giám sát là nơi bạn có các biến đầu vào (x) và một biến đầu ra (Y) và một thuật toán được sử dụng để học hàm ánh xạ đầu vào và đầu ra.
Mục đích là tìm hàm ánh xạ sao cho khi dữ liệu đầu vào mới (x) đến, nó có thể dự đoán các biến đầu ra (Y) cho dữ liệu đó.
Các bài toán của học có giám sát có thể được nhóm lại thành hai vấn đề chính là mô hình hồi quy và phân loại:
- Phân loại: Bài toán được xem phân loại là khi biến đầu ra là một danh mục, chẳng hạn như “có” hoặc “không” hoặc “thiệt hại” và “không có thiệt hại”.
- Hồi quy: Bài toán được xem hồi quy là khi biến đầu ra là một giá trị thực, chẳng hạn như “năng lượng tiêu thụ”.
2.2 Học không giám sát
Học không giám sát là bài toán chỉ có dữ liệu đầu vào (X) và không có biến đầu ra tương ứng. Mục tiêu của học không giám sát là mô hình hóa cấu trúc hoặc sự phân phối cơ bản của dữ liệu để hiểu thêm về dữ liệu. Lý do mà mô hình này được gọi là học không giám sát là vì không có nhãn chính xác hoặc giá trị dự đoán cụ thể.
Học không giám sát có thể được chia thành 2 loại bài toán phân cụm và liên kết.
- Phân cụm: bài toán phân cụm là để tìm ra mối liên kết giữa các nhóm trong 1 cơ sở dữ liệu
- Kết hợp: Bài toán về luật kết hợp là nơi để tìm ra các luật mà mô tả các phần của cơ sở dữ liệu.
3. Các kiểu training
Có 2 kiểu huấn luyện là batch training và real time training
3.1 Batch training
Việc chạy các thuật toán yêu cầu tập dữ liệu đầy đủ cho mỗi lần cập nhật có thể tốn kém khi dữ liệu lớn. Thay vào đó, chúng ta có thể thực hiện đào Batch training. Batch training là mô hình đào tạo được sử dụng phổ biến nhất, trong đó thuật toán học máy được huấn luyện trên 1 Batch hoặc nhiều Batchs trên dữ liệu có sẵn. Sau khi dữ liệu này được cập nhật hoặc sửa đổi, mô hình có thể được đào tạo lại nếu cần. Mặc dù không hoàn toàn cần thiết để thực hiện một mô hình trong sản xuất, nhưng Batch training cho phép có một mô hình được làm mới liên tục.
3.2 Real time training
Real time training bao gồm một quá trình liên tục nhận data mới và cập nhập mô hình nhằm mục đích để tang khả năng dự đoán. Việc này có thể được thực hiện với mô hình Spark Structured Streaming bằng việc sử dụng Streaming LinearRegressionwithSGD
4. Các cách triển khai mô hình
Một khi mô hình đã được đào tạo, sau đó nó phải được triển khai vào các ứng dụng thực tế. Thuật ngữ “triển khai mô hình” có thể được thay thế bằng các thuật ngữ như “phục vụ mô hình” hoặc “dự đoán”. Mặc dù có một ý nghĩa về thời điểm nên sử dụng thuật ngữ nào, nhưng đó là sự phụ thuộc vào ngữ cảnh. Tuy nhiên, tất cả đều đề cập đến quá trình tạo ra các giá trị dự đoán từ nguồn dữ liệu vào.
4.1 Operational database
Cách triển khai này đôi khi có thể được coi như là triển khai theo thời gian thực vì dữ liệu được cung cấp khi cần thiết. Tuy nhiên nó vẫn được xem như là phương pháp Batch. Quy trình huấn luyện Batch có thể chạy bất cứ thời gian nào miễn là thích hợp cho hệ thống. Nhưng sẽ thường được chạy vào ban đêm khi nhà máy không còn làm việc. Sau đó 1 cơ sở dữ liệu sẽ được cập nhập những dự đoán mới nhất. Và sáng hôm sau, ứng dụng máy học có thể nạp những dự đoán để đưa ra hành động thích hợp.
Một vấn đề tìm ẩn của kiểu triển khai này là nguồn dữ liệu có thể thay đổi mà không dự đoán trước được kể từ lần cuối khi mà đã huấn luyện xong. Và dự đoán tại thời điểm này có thể sẽ khác. Và nó có thể dẫn đến vài vấn đề về kỹ thuật.
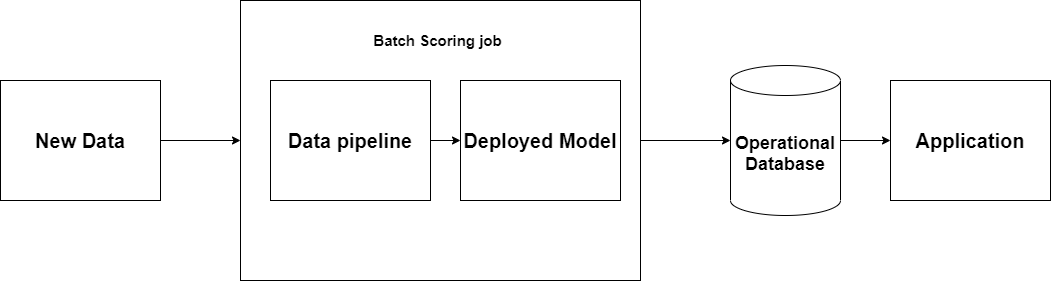
(Figure 3: Operational database)
Chú thích: Apache Spark là 1 framework rất hữu dụng cho quy trình Batch. Tuy nhiên, một số người thường tách những hàm trong Pyspark với một số hàm hữu dụng trong python, đặc biệt là thư viện Scikit-library. Apache spark rất giỏi trong việc xử lý các vấn đề tính toán tổng quát khi thực thi nó song song trên nhiều nút và chia nhỏ dữ liệu cho phù hợp với công việc. Vì Spark 2.3 cho phép sử dụng UDF dựa trên Pandas với Apache Arrow, điều này giúp tăng tốc đáng kể. Nếu mô hình được tạo bằng cách sử dụng thư viện Scikit-learning, nó vẫn có thể sử dụng sức mạnh xử lý song song của Spark trong việc triển khai mô hình batch thay vì chạy đơn lẻ.
4.2 Real-time Model Serving
Trong một số bài toán yêu cầu mô hình có thể đưa ra dự đoán dựa trên nguồn dữ liệu thời gian thực. Có một số cách triển khai có thể được sử dụng để làm cho việc này.
4.2.1 Sử dụng Kafka and Spark Streaming
Một cách để cải thiện operational database đã nói ở trên là thực hiện một thứ gì đó sẽ có khả năng sẽ liên tục cập nhật cơ sở dữ liệu khi dữ liệu mới được tạo ra. Một giải pháp là sử dụng một nền tảng scale messaging như Kafka để gửi dữ liệu mới có được đến quá trình Spark Streaming đang. Quy trình Spark hiện có thể đưa ra dự đoán mới dựa trên dữ liệu mới và tìm nạp nó vào operational database.
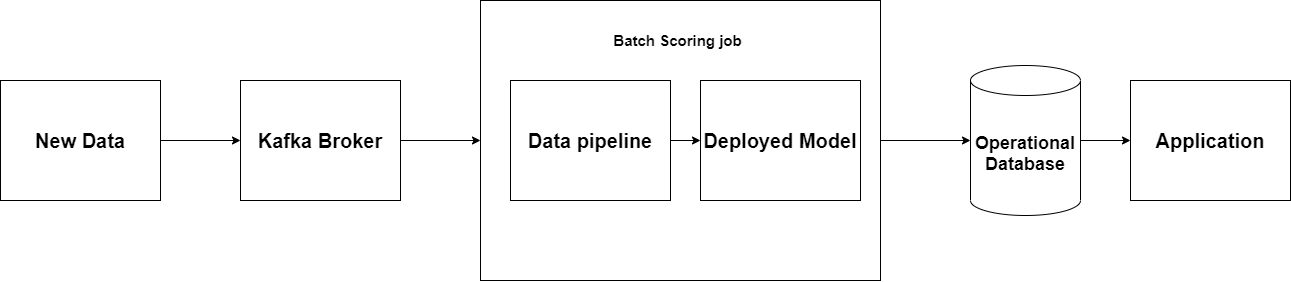
(Figure 4: Triển khai mô hình với Kafka)
Việc này đc sử dụng để cải thiện dự đoán không chính xác tiềm ẩn cho những ứng dụng máy học trên dữ liệu bị lỗi thời.
4.2.2 Web Service API
Một cách khác để triển khai mô hình là sử dụng web service. CDSW triển khai mô hình thời gian thực bằng cách triển khai một vùng bao gồm mô hình và các thư viện cần thiết để xây dựng API REST. API này sẽ nhận một yêu cầu với dữ liệu JSON, cung cấp dữ liệu đến mô hình và trả về giá trị dự đoán.
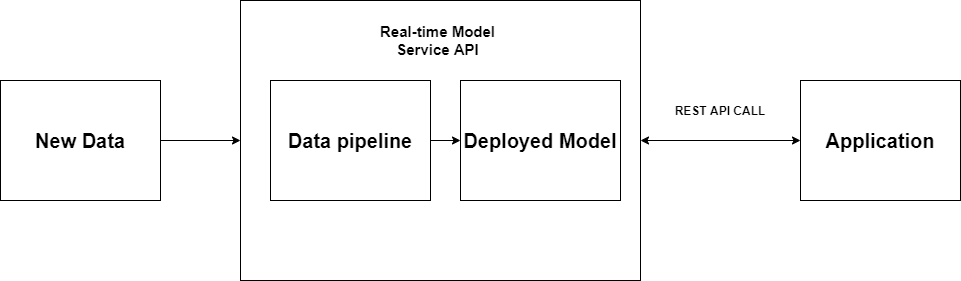
(Figure 5: Triển khai mô hình với API)
Một điều cần chú ý với kiểu triển khai này là quản lý cơ sở hạ tầng để đối phó với với nhiều tải đến đồng thời. Nếu có một số yêu cầu xảy ra cùng một lúc, sẽ có nhiều lệnh gọi API đến. Nếu không có đủ dung lượng, các yêu cầu có thể mất nhiều thời gian để phản hồi hoặc thậm chí không thành công, đây sẽ là một vấn đề đối với ứng dụng. Ngoài ra, hệ thống có thể bị ngừng hoạt động do quá tải.
4.3 Device Scoring
Một cách khác để triển khai mô hình là chuyển các mô hình ML sang phải cạnh và đưa ra dự đoán trên thiết bị cạnh (“edge device”. Thuật ngữ thiết bị cạnh có nghĩa là bất kỳ thứ gì được kết nối với đám mây, trong đó đám mây đề cập đến như Microsoft Azure hoặc máy chủ từ xa của một công ty. Điều này cho phép các mô hình vẫn có thể sử dụng được trong các tình huống có dung lượng mạng hạn chế và đẩy các yêu cầu tính toán ra khỏi cụm trung tâm đến bản thân các thiết bị.
Thật không may, cách tiếp cận này sẽ chỉ hoạt động với những trường hợp tương đối hiếm khi các thiết bị IoT khá mạnh, như máy tính để bàn hoặc máy tính xách tay. Ngoài ra, các thư viện newral network như CNTK và Keras / TensorFlow được thiết kế để đào tạo các mô hình một cách nhanh chóng và hiệu quả, nhưng nói chung, chúng được thiết kế để có hiệu suất tối ưu khi thực hiện imput –output với một mô hình được đào tạo. Nói tóm lại, giải pháp triển khai mô hình trên thiết bị IoT trên thế giới còn khó thực hiện.
Tóm lại, ý tưởng chính là có thể đưa ra dự đoán mới dựa trên thông tin mô hình có trong thiết bị di động mà không cần kết nối lại với cụm đám mây ở trung tâm.
5. Giám sát Hiệu suất Mô hình
Độ lệch của mô hình
“Độ lệch mô hình” là một thuật ngữ đề cập đến sự suy giảm khả năng dự đoán của mô hình do những thay đổi trong môi trường và thêm vào đó mối quan hệ giữa các biến.
Có ba loại độ lệch môi hình:
- Độ lệch về khải niệm là một kiểu độ lệch mô hình mà các thuộc tính của biến phụ thuộc thay đổi theo cách không lường trước được. Ví dụ, trong ứng dụng dự đoán thời tiết, có thể có một số thay đổi như nhiệt độ, áp suất, độ ẩm.
- Độ lệch về dữ liệu là một kiểu độ lệch mô hình trong đó các thuộc tính của (các) biến độc lập thay đổi. Ví dụ về độ lệch dữ liệu bao gồm những thay đổi trong dữ liệu do tính thời vụ, những thay đổi trong sở thích của người tiêu dùng, việc thêm các sản phẩm mới, v.v.
- Thay đổi dữ liệu upstream đề cập đến các thay đổi dữ liệu hoạt động trong dữ liệu. Một ví dụ về điều này là khi một tính năng không còn tạo ra giá trị mới nữa, dẫn đến thiếu giá trị. Một ví dụ khác là một sự thay đổi trong đo lường (ví dụ. dặm sang km).
Nếu mô hình giảm xuống dưới ngưỡng hiệu suất có thể chấp nhận được, thì một quy trình mới để tạo ra mô hình sẽ được bắt đầu lại và mô hình mới được đào tạo đó sẽ được triển khai thay thế.
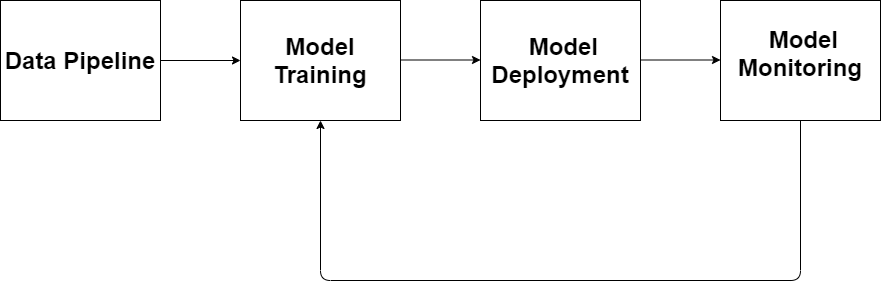
(Figure 6 Giam sát hiệu suất mô hình)
Đôi khi, cũng sẽ có lúc đầu vào thay đổi khiến các tính năng đã chọn không còn phù hợp với kết quả dự đoán. Nó dẫn đến hoạt động kém của mô hình. Nó cũng rất quan trọng khi phải quay lại nhiệm vụ phân tích để nhìn lại toàn bộ quá trình. Điều này có thể yêu cầu thêm hoặc loại bỏ một số tính năng không liên quan. Tóm lại, quá trình giám sát mô hình là một phần quan trọng trong vòng đời mô hình.
Kết luận
Nói chung, nó có nhiều ý tưởng để áp dụng mô hình học máy vào sản xuất. Không có tiêu chuẩn về cách mọi thứ nên được thực hiện. Mỗi nhà máy, mỗi thiết bị sẽ có những cách sử dụng machine learning khác nhau. Chìa khóa ở đây là hiểu rõ về dữ liệu và mô hình. Hiệu suất đo lường của mô hình tác động thế nào đến với sản xuất. Đây là bài viết cuối cùng của loạt bài này. Nếu bạn có bất kỳ câu hỏi nào, vui lòng liên hệ với Daviteq – Cảm biến đo rung theo email info@daviteq.com.
How to add WS433 sensor Node ID automatically




Comments are closed.