
 Tiếng Việt
Tiếng Việt
In the previous article, the data analysis task was introduced, the next important task is how to apply machine learning into manufacturing and make it gain benefit for the business. There are different approaches to putting machine learning into business which has various positive impacts. This article will be divided into three main parts. The first part introduces some definitions of the machine learning model and types of a machine learning model. The second part gives a definition of each type of training model. The final part is about how to deploy and improve a machine learning model.
1. Model definition
This is a key term that should be understood clearly. The term “model” is used widely in business. For the purpose of this article, “the model” is defined as a combination of an algorithm and configuration details that can be used to make a new prediction based on a new set of input data. It is a black box that can take in new raw data input and make a prediction. A model will be trained over a set of data. It is provided an algorithm that can use to reason over and learn from the data sources.
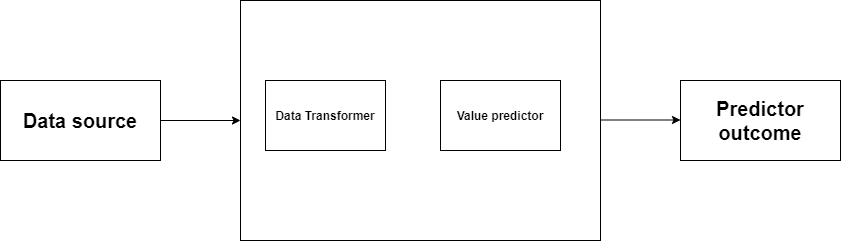
Figure 1: Model definition
There are many tools, library and software programs that are able to create model easily. For example, Sklearn library and Spark are very popular.
2. Type of machine learning model option
Machine learning can be divide into two major types (depend on problem), which are supervised learning and unsupervised learning.
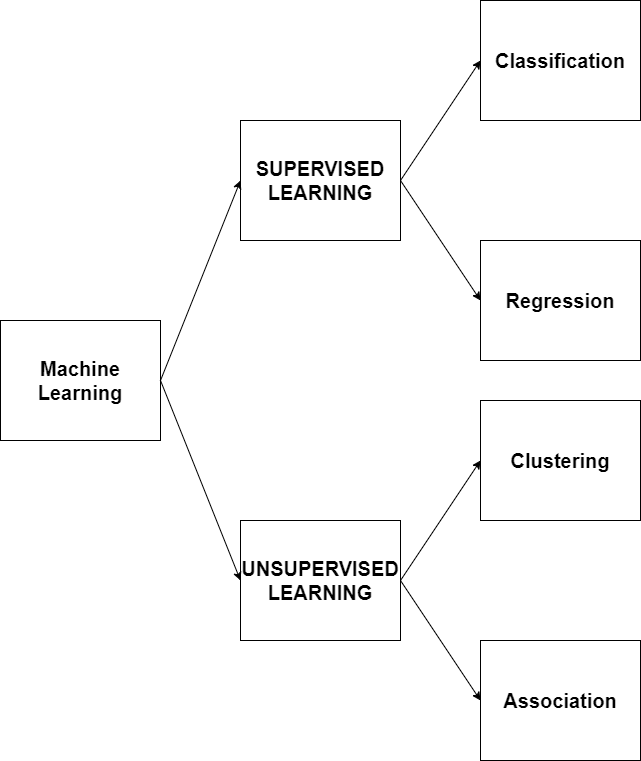
(Figure 2: Type of machine learning option)
2.1 Supervised learning
The majority of practical machine learning uses supervised learning. Supervised learning is where you have input variables (x) and an output variable (Y) and an algorithm is used to learn the mapping function from the input to the output.
Y = f(x)
The goal is to approximate the mapping function so well that when the new input data (x) come, it can predict the output variables (Y) for that data.
Supervised learning problems can be further grouped into regression and classification problems
- Classification: A classification problem is when the output variable is a category, such as “yes” or “no” or “damage” and “no damage”.
- Regression: A regression problem is when the output variable is a real value, such as “energy consumption”.
2.2 Unsupervised machine learning
Unsupervised learning is where you only have input data (X) and no corresponding output variables.
The goal of unsupervised learning is to model the underlying structure or distribution in the data in order to learn more about the data.
The reason this is called unsupervised learning is that there is no correct answer or specific prediction value.
Unsupervised learning can be further grouped into clustering and association problems.
- Clustering: A clustering problem is where inherent grouping in the data are investigated.
- Association: An association rule learning problem is where you want to discover rules that describe large portions of your data
3. Type of training options
There are two types of training options. The two main approach are batch and real-time
3.1 Batch training
Running algorithms which require the full dataset for each update can be expensive when the data is large. In order to scale inferences, we can do Batch training. Batch training is the most commonly used model training process, where a machine learning algorithm is trained in a batch or batches on the available data. Once this data is updated or modified, the model can be trained again if needed. While not fully necessary to implement a model in production, batch training allows to have a constantly refreshed version of models.
3.2 Real time training
Real-time training involves a continuous process of taking in new data and updating consequently to improve its predictive power. This can be done with Spark Structured Streaming using Streaming LinearRegressionwithSGD.
4. Model deployment options
Once the model has been trained, it must then be deployed into production. The term “model deployment” can be replaced with terms like “model serving”, “model scoring”, or “predicting”. While there is a nuance as to when to use which term, it’s context-dependence. However, it all refers to the process of creating predicted values from the data source.
4.1 Operational Databases
This option is sometimes considered to be real-time as the information is provided “as it needed”, however, it is still a batch method. A batch process can be run at any time that is suitable for the system (usually it is at night when the factory is no longer in operation). After that, an operational database is updated with the most recent prediction. In the next morning, the application can fetch this prediction in order to take action this.
One potential problem of this kind of deployment is that a data source may have changed unpredictably since the last batch job was run. The prediction at this point could be different. It can lead to some technical issues.
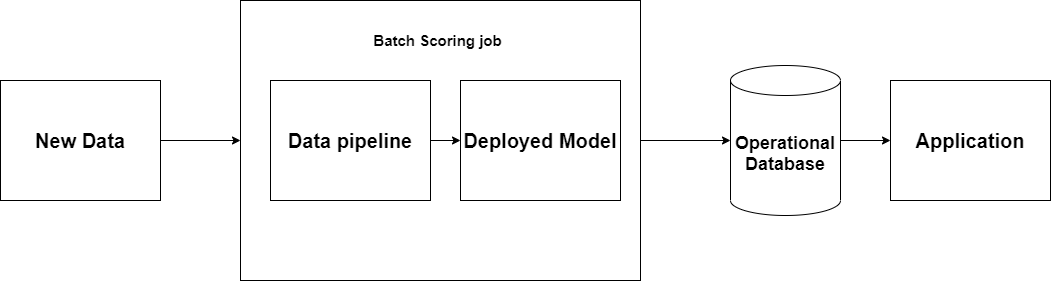
(Figure 3: Operational database)
Notes: Apache spark is a very useful framework in the Batch process. However, some people seem to separate Pyspark function with some other useful python functions, specifically scikit-learn library. Apache spark is good at taking generalized computing problems executing it in parallel across many nodes and splitting up the data to suit the job. Since Spark 2.3 allow use Pandas based UDF with Apache Arrow, which significantly speed this up. If the model is created by using Scikit-learn, it is still possible to use the parallel processing power of Spark in a batch scoring implementation rather than having to run scoring on a single node running plain odd python.
4.2 Real-time Model Serving
In some problems that requires the model can make a prediction based on real-time data sources. There are several deployment pattern that can be used to make this work.
4.2.1 Online Scoring with Kafka and Spark Streaming
One way to improve the operational database process talked above is to implement something that will continuously update the database as new data is generated. One solution is that use a scalable messaging platform like Kafka to send newly acquired data to long running Spark Streaming process. The Spark process now can make a new prediction based on the new data and fetch it into operational database.
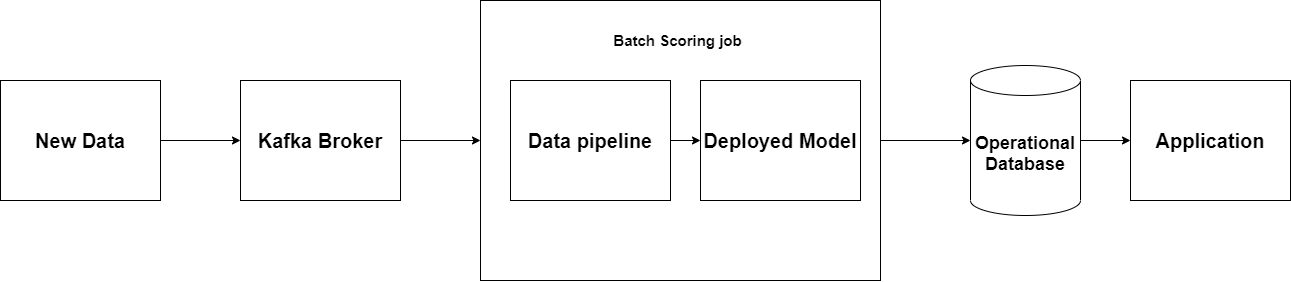
(Figure 4: Deployment with Kafka)
This use to improve the potential incorrect prediction for an application on outdated data.
4.2.2 Web Service API
Another way to deploy model is by using a web service wrapper around the model. CDSW implements a real-time model serving by deploying a container that includes the model and necessary libraries to build a REST API. This API will take a request with JSON data, deliver data to the model, and return a prediction value.
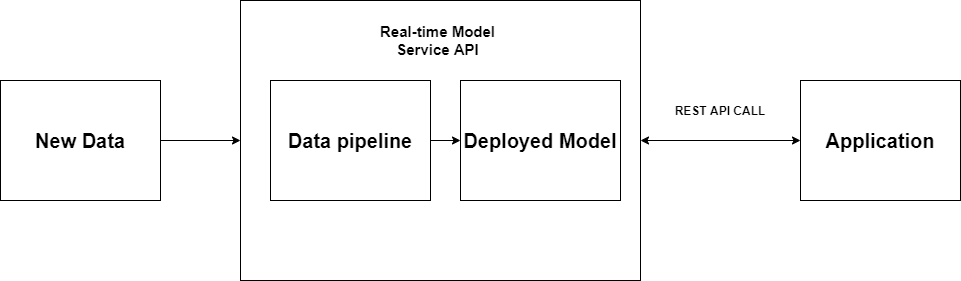
(Figure 5 Web Service API)
The one thing to look out for with this deployment pattern is managing infrastructure to deal with the load associated with concurrency. If there are several requests that happen at the same time, there will be multiple API calls placed to the endpoint. If there is not sufficient capacity, requests may take a long time to respond or even fail, which will be an issue for the application. In addition, the system may be down due to overload.
4.3 Device Scoring
Another type of model serving option is to move the ML models right to the edge and make a prediction on an edge device. The term edge device means anything connected to the cloud, where cloud refers to something like Microsoft Azure or a company’s remote server. This allows models to still be usable in situations with limited network capacity and push the compute requirements away from a central cluster to the devices themselves.
Unfortunately, this approach will work only with relatively rare situations where IoT devices are quite powerful, perhaps along the lines of a desktop PC or laptop. Also, neural network libraries such as CNTK and Keras/TensorFlow were designed to train models quickly and efficiently, but in general, they were not necessarily designed for optimal performance when performing input-output with a trained model. In short, the easy solution for deploying a trained ML model to an IoT device on the edge is rarely feasible.
In conclusion, the main idea is being able to make a new prediction based on the model information contained in the portable model format, without needing to connect back to the central model training cluster.
5. Monitoring Model Performance
After the model is deployed into production and providing utility to manufacturing, it is important to monitor how well the model is performing. There are several aspects of performance to consider, and each will have its own measurement that will have an impact on the life cycle of the model
Model drift
Model drift is a term refers to the degradation of a model’s prediction power due to changes in the environment, and thus the relationships between variables.
There are three type of model drift
- Concept drift is a type of model drift where the properties of the dependent variable changes in unforeseen way. For example, in the weather prediction application, there may be several target concepts such as temperature, pressure, humidity.
- Data drift is a type of model drift where the properties of the independent variable(s) change(s). Examples of data drift include changes in the data due to seasonality, changes in consumer preferences, the addition of new products, etc…
- Upstream data changes refer to operational data changes in the data pipeline. An example of this is when a feature is no longer being generated, resulting in missing values. Another example is a change in measurement (eg. miles to kilometers).
If the model falls below an acceptable performance threshold, then a new process to retain the model is initiated, and that newly trained model will be deployed.
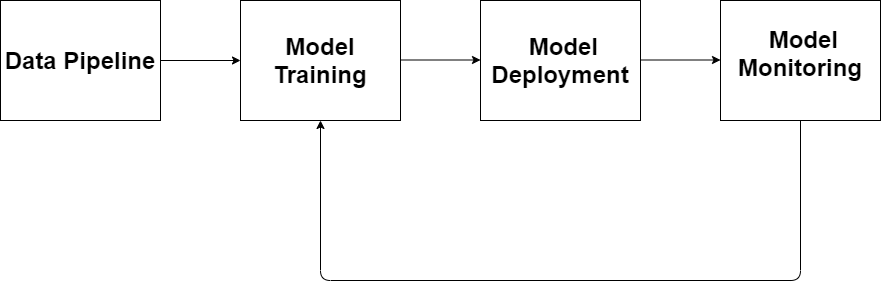
(Figure 6: Model drift)
Sometimes, there will also be times where the input has changed so that the features which were selected are no longer relevant to the prediction result. It leads to the poor performance of the model. It is important to go back to the analytic task to re-look a whole process. This may require to add/eliminate some irrelevant features. In conclusion, the model monitoring process is a critical part of the model lifecycle.
Conclusion
In general, it has many ideas to apply machine learning models into manufacturing. There is no standard as to how things should be implemented. Each factory, each equipment will have different ways to use machine learning. The key here is to have a good understanding of the data and model. Knowing what model performance measurement matter to the manufacturing. This is the final article of this series. If you have any questions, feel free to contact us at info@daviteq.com.
Wireless lidar people counter Daviteq




Comments are closed.